count(*)、count(1)哪个更快?面试必问:通宵整理的
一、你是如何理解Count(*)和Count(1)的?
这两个并没有区别,不要觉得 count() 会查出全部字段,而 count(1) 不会。所以 count() 会更慢,你觉得 MySQL 作者会这么做吗?
可以很明确地告诉你们 count() 和 count(1) 是一样的,而正确有区别的是 count(字段)。如果你 count() 的是具体的字段,那么 MySQL 会判断某行记录中对应字段是否为 null,如果为 null 就不会进行统计了。因此 count(字段) 的结果可能会小于 count() 和 count(1)。
另外,直接执行 select (*) from t1; 时,也可以利用到索引的,并不一定是全表扫描,也可以扫描某个索引 B 树的叶子节点,从而得到总条数,因为不管是什么索引,主键索引还是辅助索引,实际上它们在叶子节点的数量是一样的,只不过字段数不一样,主键索引存了全部字段,而辅助索引只存了定义的索引字段 主键字段,所以通常辅助索引是更占用空间的,因此遍历起来也会更快,但是记录条数是一样的。
二、你是如何理解最左前缀原则的?
这个原则表明,只有在复合索引的左侧部分的列上,条件才能被优化。换句话说,当使用复合索引时,查询的条件应该从索引的最左侧列开始,才能最大化利用索引
我们创建一个简单的示例表,命名为employees,并在其上创建一个复合索引。表结构如下:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INT,
department VARCHAR(50),
INDEX idx_name_age (last_name, first_name, age)
);
接下来,我们插入一些实例数据
INSERT INTO employees (first_name, last_name, age, department) VALUES
('John', 'Doe', 30, 'HR'),
('Jane', 'Doe', 25, 'IT'),
('Mary', 'Smith', 35, 'Finance'),
('Michael', 'Johnson', 40, 'IT'),
('Emily', 'Davis', 29, 'HR');
符合最左前缀原则的查询SQL
SELECT * FROM employees WHERE last_name = 'Doe' AND first_name = 'Jane' AND age=25;
SELECT * FROM employees WHERE first_name = 'Jane' AND last_name = 'Doe' AND age=30;
SELECT * FROM employees WHERE age=30 AND last_name = 'Doe' AND first_name = 'Jane';
对于上面这些查询,MySQL会使用idx_name_age索引,从这能够看出,以上SQL都能走索引,和Where条件顺序没有关系
---- ------------- ----------- ------- --------------- --------- --------- ------ ------- -------------
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
---- ------------- ----------- ------- --------------- --------- --------- ------ ------- -------------
| 1 | SIMPLE | employees | range | idx_name_age | idx_name_age | 100 | NULL | 2 | Using where |
---- ------------- ----------- ------- --------------- --------- --------- ------ ------- -------------
在这个执行计划中,我们看到type是range,说明MySQL正在使用idx_name_age索引,并且只检查了大约2行数据。
那如果把last_name去掉呢?
不符合最左前缀原则的查询
SELECT * FROM employees WHERE first_name = 'Jane' AND age = 25;
对于这个查询,MySQL不会使用复合索引idx_name_age,因为它没有从最左侧的列last_name开始。
通过Explain执行计划,查看索引执行情况
---- ------------- ----------- ------- --------------- ------ --------- ------ ------- -------------
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
---- ------------- ----------- ------- --------------- ------ --------- ------ ------- -------------
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 5 | Using where |
---- ------------- ----------- ------- --------------- ------ --------- ------ ------- -------------
在这个执行计划中,我们看到type是ALL,这意味着MySQL没有使用任何索引,而是进行了全表扫描,这样效率较低。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
总结
从这可以看出,所谓的最左前缀原则的“最左”,并不是指where条件中的last_name一定要在最左边,而是指where条件中一定要给出定义联合索引的最左边字段,比如我们定义“last_name, first_name, age”联合索引的SQL为:
INDEX idx_name_age (last_name, first_name, age)
其中last_name字段是最左边的字段,因此如果想要走idx_name_age索引,那么SQL一定要给出last_name字段的条件,这才是“最左”的意思。
三、你是如何理解行锁、GAP锁、临健锁的?
1、行数
行锁是对具体数据行的锁定,允许多个事务并发操作不同行,只有在同一行上进行写入时才会阻塞其他事务
假设我们有如下表结构和数据:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INT,
department VARCHAR(50)
);
如果事务A更新了某个特定员工的信息:
-- 事务A
START TRANSACTION;
UPDATE employees SET age = 31 WHERE last_name = 'Doe';
在这个过程中,行锁会被加在last_name = 'Doe'所对应的行上(即John和Jane)。如果此时事务B尝试更新同一行:
-- 事务B
START TRANSACTION;
UPDATE employees SET age = 29 WHERE last_name = 'Doe';
事务B会被阻塞,直到事务A提交或回滚,因为事务A、事务B加的都是排它锁,也叫悲观锁。这样行锁确保了数据的一致性。
GAP锁
行锁锁的是某一行,而GAP锁锁的是行前面的间隙,注意只是行前面的间隙,你可能会问那表的最后一行前后都有间隙啊,最后一行后面的间隙不锁吗?
当然会锁了,只不,过是交给了一个叫做PAGE_NEW_SUPREMUM的记录来说,你可以理解为PAGE_NEW_SUPREMUM记录是InnoDB默认的,它固定作为最后一条记录,因此只要锁住PAGE_NEW_SUPREMUM前面的间隙,就相当于锁住了我们所理解的最后一行后面的间隙。
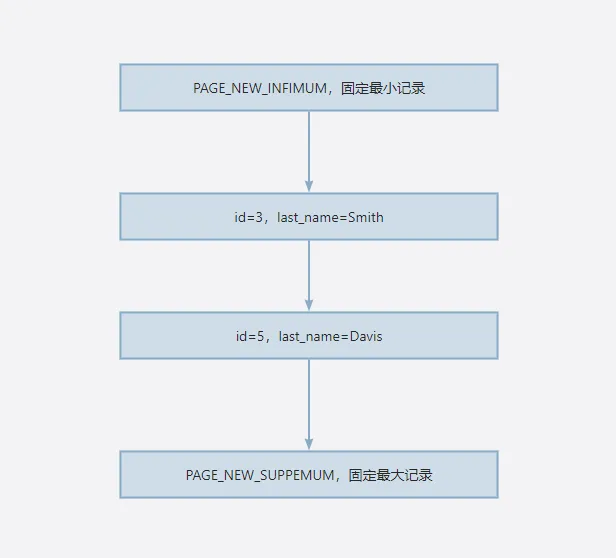
临健锁(Next-Key Lock)
临界锁是行锁和GAP锁的结合,锁定具体的数据行以及行之间的空隙。它用于确保在一个范围内的查询中,不仅防止了幻读,还能保护行数据
继续使用之前的例子,假设我们执行了如下操作:
-- 事务D
START TRANSACTION;
SELECT * FROM employees WHERE last_name >= 'D' FOR UPDATE;
在此查询中,MySQL会对所有last_name为'D'及其后的行加上行锁,同时对'D'之前的空隙加上GAP锁,这样可以防止在该范围内插入新的行。
四、你是如何理解MVCC的?
OCR识别结果出现了一些错误和混乱,导致内容不够清晰。虽然识别不是很理想,但我将根据我的理解和相关知识,概述该图片可能传达的内容。
如何理解MVCC?
所谓MVCC就是多版本并发控制,MySQL为了实现可重复读这个隔离级别,而且为了不采用锁机制来实现可重复读,所以采用MVCC机制来实现。
主要概念
-
ReadView(读取视图):
- 当一个事务开始时,MVCC会创建一个
ReadView,该视图记录了当前可见的所有版本,包括哪些事务是活跃的,哪些事务已经提交。
- 当一个事务开始时,MVCC会创建一个
-
事务ID:
- 每个事务都有一个唯一的事务ID。在
ReadView中,会记录当前事务的ID、最小事务ID和最大事务ID。
- 每个事务都有一个唯一的事务ID。在
-
可见性规则:
- 如果一个事务的ID:
- 大于
ReadView中的最大事务ID:这个事务的更改对当前事务不可见。 - 属于
ReadView中的活跃事务:则该事务的更改不可见,因为该事务还在进行中。 - 小于
ReadView中的最小事务ID:该事务的更改是可见的,因为它已经提交。
- 大于
- 如果一个事务的ID:
MVCC的工作流程
-
创建 ReadView:
- 当事务开始时,MVCC会生成一个
ReadView。它会包含当前事务的ID、活跃事务的ID以及最大和最小事务ID。
- 当事务开始时,MVCC会生成一个
-
读取数据:
- 当事务读取数据时,它将参考
ReadView中的信息,以确定哪些版本的数据是可见的。
- 当事务读取数据时,它将参考
-
更新数据:
- 当事务更新数据时,MVCC不会直接覆盖原有的数据,而是创建一个新的版本。只有在所有引用该数据的事务完成后,才会清理旧版本。
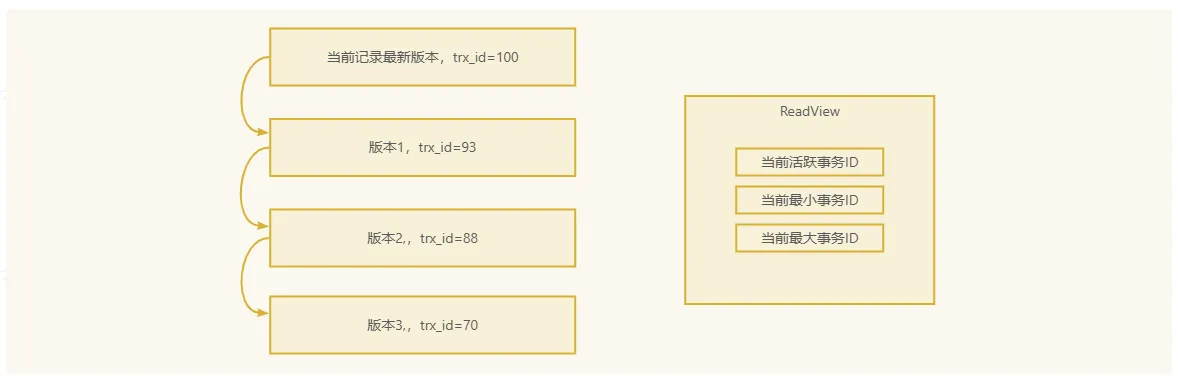
总结
MVCC允许多个事务在不干扰彼此的情况下同时进行操作,这极大地提高了数据库的并发性能。通过维护数据的多个版本,MVCC保证了数据的一致性和隔离性,同时减少了锁的竞争。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
五、你是如何理解Online DDL的?
Online DDL 是指在不影响数据库服务的情况下,修改数据库表的结构。通俗点说,就是我们可以在数据库正常运作的同时,对表进行调整,比如新增列、修改字段类型、添加索引等,而不需要停机维护。
般的DDL操作,比如新增一个字段,会有以下几个步骤
1. 解析与检查
MySQL 首先会对 DDL 语句进行解析,确保语法正确。例如:
ALTER TABLE users ADD COLUMN age INT;
MySQL 会检查表 users 是否存在,新增的 age 字段是否与已有的字段冲突(比如字段名重复),数据类型是否支持等。
2. 表的元数据锁(metadata lock)
在进行任何表结构变更之前,MySQL 会对表加一个元数据锁(MDL)。元数据锁的作用是防止在变更结构的同时,其他 DDL 操作对表进行修改,保证表结构一致性。
类比:元数据锁就像在超市里装货架时,防止其他人也来同时更改货架位置,避免混乱。
3. 创建临时表
当我们执行 ALTER TABLE 语句时,MySQL 会创建一个临时表。这个临时表是现有表的一个复制品,并且会按照我们的要求增加新的字段。
临时表的步骤:
- 复制原表结构:MySQL 会复制原表的结构到一个临时表中,并加上我们新增的字段,比如
age。 - 复制数据:MySQL 将原表中的所有数据行逐行复制到临时表中,同时为每一行填充新增加字段的默认值(如果有)。
类比:这就像超市货架升级时,先在仓库里搭建一个新的货架模型,放置相同的商品,同时增加新的商品存放区。
4. 切换表
当 MySQL 完成了数据复制后,它会将原表和临时表进行替换。此时,临时表变成了正式的表,包含了新字段。
- 在这个过程中,所有的 DML(增删改查)操作都会暂时被挂起,直到替换完成。这段时间很短暂,对服务的影响非常小。
类比:就像仓库里的新货架搭建好后,把它搬进超市,同时替换掉旧货架。顾客几乎不会察觉到这个过程。
5. 删除旧表
原始的表被新表替换后,MySQL 会自动删除旧表的元数据,释放空间。这一步在后台完成,不影响数据库的正常操作。
6. 释放锁
当所有操作完成后,MySQL 会释放元数据锁,允许其他 DDL 或 DML 操作继续进行。
总结:
- 解析语句并检查合法性。
- 对表加元数据锁(防止冲突的结构变更)。
- 创建临时表,并将数据从旧表复制到临时表。
- 替换旧表,删除旧表的元数据。
- 释放锁。
注意:这种方法在不使用 Online DDL 的情况下,可能导致大量的数据复制操作,进而对性能有影响,尤其是表数据量较大时。
六、你知道哪些情况下会导致索引失效
在 MySQL 中,索引是提高查询效率的关键工具,但有时可能会遇到索引失效的情况,导致查询性能大幅下降。这种情况通常与查询语句的写法、数据类型的选择以及数据库的优化机制有关。下面是几种常见会导致索引失效的场景:
1. 使用 LIKE 时通配符放在前面
如果在 LIKE 语句中,通配符 % 放在字符串的开头,会导致索引失效。因为在这种情况下,MySQL 无法通过索引快速定位到符合条件的记录,而需要扫描所有记录。
示例:
SELECT * FROM users WHERE name LIKE '
相关文章
 优化GreatSQL日志文件空间占用 GreatSQL对于日志文件磁盘空间占用,做了一些优化,对于binlog、...03-18
优化GreatSQL日志文件空间占用 GreatSQL对于日志文件磁盘空间占用,做了一些优化,对于binlog、...03-18 "数据约束条件" date: 2022-11-24T21:24:31 08:00 draft: false MySQL字段约束条件 无符号, 零填充...03-18
"数据约束条件" date: 2022-11-24T21:24:31 08:00 draft: false MySQL字段约束条件 无符号, 零填充...03-18
【GreatSQL优化器-16】INDEX_SKIP_SCAN
【GreatSQL优化器-16】INDEX_SKIP_SCAN 一、INDEX_SKIP_SCAN介绍 GreatSQL 优化器的索引跳跃扫描(Index Ski...03-18 MySQL 是一个非常流行的开源关系数据库管理系统,在各种应用场景中都得到了广泛的应用。随...03-18
MySQL 是一个非常流行的开源关系数据库管理系统,在各种应用场景中都得到了广泛的应用。随...03-18 🤖 DB-GPT 是一个开源的 AI 原生数据应用程序开发框架,具有 AWEL(代理工作流表达式语...03-18
🤖 DB-GPT 是一个开源的 AI 原生数据应用程序开发框架,具有 AWEL(代理工作流表达式语...03-18
GreatSQL 8.0.32-27 GA (2025-3-10)
GreatSQL 8.0.32-27 GA (2025-3-10) 版本信息 发布时间:2025年3月10日 版本号:8.0.32-27, Revision aa66a38591...03-18 6. MySQL 索引的数据结构(详细说明) @目录6. MySQL 索引的数据结构(详细说明)1. 为什么使用索引2...03-18
6. MySQL 索引的数据结构(详细说明) @目录6. MySQL 索引的数据结构(详细说明)1. 为什么使用索引2...03-18- @Override @Transactional(rollbackFor = Exception.class) public void batchInsertDeviceData(IotMsgNotifyData iotMsgNotifyDa...03-18
 个人Qt项目总结——数据库查询断言问题 问题: 当我使用MySQL数据库的查询操作时, 如果查询...03-18
个人Qt项目总结——数据库查询断言问题 问题: 当我使用MySQL数据库的查询操作时, 如果查询...03-18- MySQL 是一种广泛使用的关系数据库管理系统,MySQL 8 是其最新的主要版本,结合了出色的性能和...03-18
最新评论